딥러닝(Deep Learning)
딥러닝은 인간의 뇌정보처리를 모방한 다층구조 신경회로망(deep neural network; DNN)을 통해 다량의 데이터로부터 특정한 기능을 수행하기 위해 패턴을 인식하거나 회기 모델을 학습하기 위한 최근 인공지능을 선도하는 머신 러닝(machine learning)의 대표 분야이다. 딥러닝은 난제로 여겨졌던 음성, 영상인식 등의 다양한 인공지능 문제를 성공적으로 해결하고 있으며 그 적용분야를 급격히 확대해 나가고 있으므로 명실상부한 인공지능 시대로 이끌고 있다.
음성 전처리 (Speech Preprocessing)

음성 향상 (Speech Enhancement)
잡음이 섞인 음성의 스펙트럼 특징으로부터 음성 성분만을 향상시키고 잡음 성분을 억제하는 기법으로, 주로 U-net 기반의 Architecture를 통한 네트워크 설계로 음성 정보의 왜곡을 최소화하면서 잡음을 억제할 수 있다.
특히 어렵게 여겨졌던 음성 스펙트럼의 phase 정보까지 함께 DNN을 통해 학습하여 0~1사이의 실수(real number) 마스크가 아닌 복소수(complex number) 마스크를 추정하는 방법이 효과적으로 음성을 향상시킬 수 있게 되었다.

▲ Deep Complex U-net (DCUnet) for Speech Enhancement
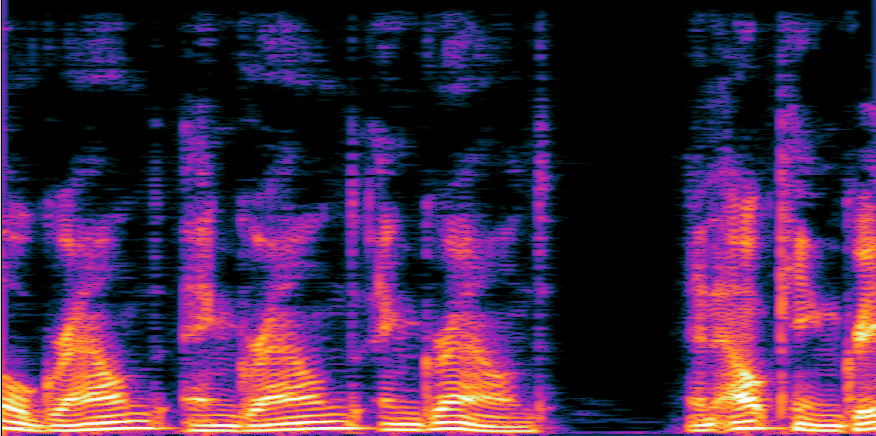
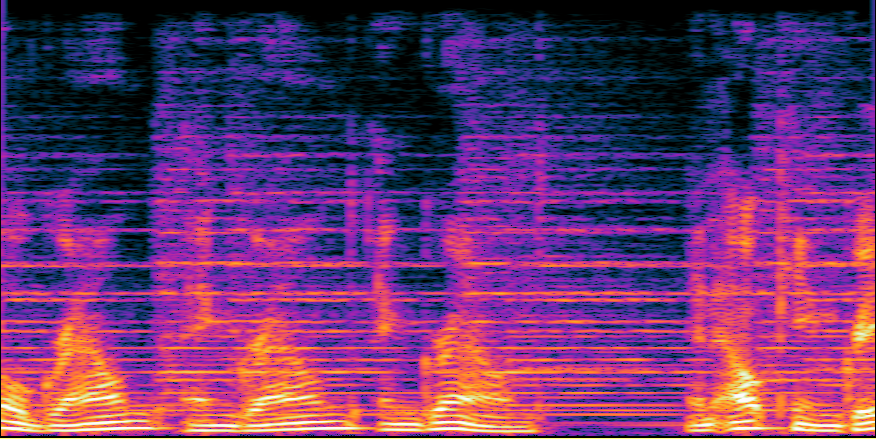

▲ DCUnet을 활용한 음성 향상 결과 : clean (좌) / Noisy input (중) / Output (우)
음원 분리 (Source Separation)
두 명이상의 발화자가 동시에 발화한 혼합 음성을 개별 발화자의 음성으로 분리하는 방법으로, 스펙트럼 영역이 아닌 시간축 영역에서의 직접적인 End-to-End 방식으로 네트워크가 설계된다. 또한 네트워크를 설계하고자, 시계열을 모델링하고자 Recurrent Neural Network (RNN), Temproal Convolutional Network (TCN), Transformer 등의 다양한 네트워크가 활용된다.

▲ Time-Domain Audio Separation Network (TasNet)
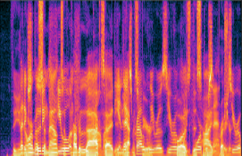
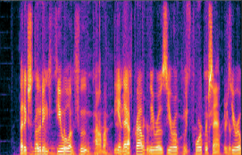

▲ Conv-TasNet을 사용한 음원 분리 결과 : Input Mixture (좌) / Output 1 (중) / Output 2(우)