[신문기사] AI용 어휘 `말뭉치` 태부족…영어 2000억개 vs 한국어 2억개
2018.07.16 11:23
https://m.news.naver.com/read.nhn?mode=LSD&sid1=105&oid=009&aid=0004184635
AI용 어휘 `말뭉치` 태부족…영어 2000억개 vs 한국어 2억개
기사입력2018.07.13 오후 5:43
최종수정2018.07.15 오후 1:50
◆ AI 인프라 외면한 정부 ◆
지난 5월 구글이 개발자대회에서 공개한 구글 어시스턴트는 사람처럼 가게에 전화를 걸어 점원과 자연스럽게 대화하며 예약을 수행해 전 세계를 놀라게 했다. 구글이 공개한 영상에 따르면 구글 어시스턴트는 전화상 음성이나 말투만 봤을 때 사람이라고 깜빡 속을 정도였다. 구글 어시스턴트는 "5월 3일 예약될까요"라고 말을 걸었다. 점원이 "잠깐만 기다리세요"라고 하자 "음…" 하며 기다리는 모습을 보였다. 상대방이 공손하게 부탁하면 칭찬을 섞어 답변도 한다. 상대의 맥락과 뉘앙스까지 파악하는 수준으로 향상된 것이다.
반면 국내 업체들이 내놓은 인공지능(AI) 어시스턴트는 말귀를 못 알아듣는다는 불만이 많다. 리서치기관 컨슈머인사이트가 지난 4월 전국 14~64세 휴대전화 사용자 1만2580명을 조사한 바에 따르면 AI 스피커 사용 경험자의 이용 만족률은 49%로 낮은 수준에 머물렀다. 불만족 이유는 '음성 명령이 잘 되지 않는다'(50%) '자연스러운 대화가 곤란하다'(41%) '소음을 음성 명령으로 오인한다'(36%) 등 순이었다. 컨슈머인사이트는 "국내 음성인식 스피커는 날씨나 일정 등 단순한 정보를 서툴게 검색하는 수준"이라고 했다.

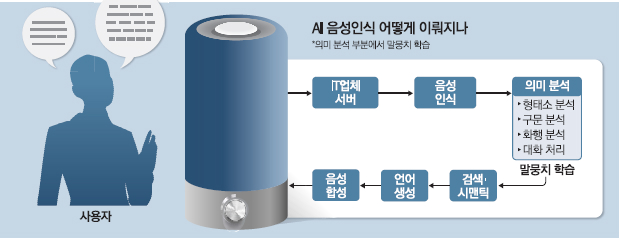
AI 스피커, 챗봇 등 자연어 처리 기술에서 파생되는 시장은 급팽창하고 있다. AI 스피커만 해도 올해 말 전 세계 설치 대수가 지난해보다 2.5배 증가한 1억대에 이를 전망이다. 말뭉치는 이처럼 급성장하는 음성인식 분야의 '씨앗'과 같은 자원이다. 마치 어린아이가 책을 읽거나 TV를 보면서 스스로 언어를 배워가는 것처럼 기계도 많은 언어를 학습할수록 성능이 좋아지기 때문이다. 하지만 말의 뉘앙스 차이까지 구별할 정도로 기술력을 갖춘 외국 AI 스피커에 비해 국내 제품의 인식률이 떨어지는 이유는 무엇일까. 전문가들은 여러 가지 차이가 있겠지만 근본적으로 국가별로 구축해 놓은 언어 데이터베이스, 한마디로 말하면 컴퓨터용 국가별 언어 인프라스트럭처에 엄청난 차이가 벌어졌기 때문이라고 지적한다. 컴퓨터가 사람 말을 인식해서 이해한 다음 이를 다시 사람 말로 표현하려면 기본적으로 사람이 말하는 언어, 말뭉치를 컴퓨터용으로 구축해 둬야 한다.
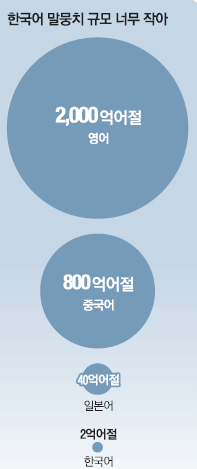
미국, 일본, 중국은 민간 기업·대학·연구소와 손잡고 20년 넘게 대규모 말뭉치 구축 사업을 지속적으로 전개해 왔다. 영어권 국가인 영국·미국은 정부와 대학, 민간 연구소, 기업이 손잡고 1990년대 초반부터 일찌감치 영어 말뭉치 구축 사업을 시작했다. 미국, 영국, 캐나다 학계는 정부 지원 아래 말뭉치 통합 작업을 했고 이 방대한 데이터베이스는 미국 브리검영대 주도 아래 하나로 구축해 약 260억개 어절을 확보했다. 학계에 따르면 현재 영어는 2000억개 넘는 어절의 말뭉치가 구축된 것으로 알려졌다. 일본은 2006년부터 정부와 대학이 공동으로 '고토노하 프로젝트'를 진행했다. 현재는 약 40억개의 말뭉치를 확보하며 앞서가고 있다. 일본 국립국어연구소는 100억개 구축을 목표로 하고 있다. 중국은 2000년대부터 본격적으로 대만과 함께 국가 예산을 바탕으로 중국어 말뭉치 구축에 나서 현재는 800억개 이상 말뭉치가 구축돼 있다. 구글은 이미 10년 전에 1900억개 영어 말뭉치를 구축했다. 이를 토대로 컴퓨터가 학습을 하기 때문에 구글 AI는 시간이 지날수록 더 잘 인식할 수밖에 없다.
자연어 처리 기술자는 "언어를 기계가 학습한다는 것은 어느 정도 자료가 쌓여야 의미 있는 결과가 나오기 때문에 음성인식 기술 업력이 짧은 기업들이 딥러닝 기술을 확보해도 인식률이 떨어질 수밖에 없다"고 했다. 이 관계자는 "요즘에는 (걸그룹) '트와이스'라고 하면 걸그룹을 뜻하지만 과거 데이터를 학습한 기계는 '두 배'로 알아듣는다"며 "기 처리 기술은 음성 '인식' 단계에서 완성도가 떨어지기 때문에 제대로 된 서비스를 할 수 없다"고 했다. 예를 들어 세종 말뭉치를 구축한 '국립국어원 언어정보나눔터'에서 '먹었니'를 검색하면 2건만 검색된다. 한 개발자는 "통상 10억어절 이상은 돼야 딥러닝을 적용할 수 있는데 2건으로는 '먹었니'를 기계에 학습시킬 수 없다"고 했다.
'비트코인' '헬조선' 등 최근 사용되는 어휘 또한 찾아볼 수 없다. 이 프로젝트가 2007년 종료된 후 더는 진행되지 않았기 때문이다. 김한샘 연세대 언어정보연구원 교수가 쓴 '말뭉치 구축의 세계 동향과 국어 말뭉치의 현주소'에 따르면 세종 말뭉치는 1990년대가 7000만건, 2000년대가 1800만건으로 절반 이상이 1980년대 이전 자료에 치우쳐 있다.
■ <용어 설명>
▷ 말뭉치 : 자연어 처리 개발에 사용되는 언어 데이터를 모아놓은 덩어리(DB)다. 음성인식 인공지능 서비스는 자연어 처리 과정을 통해 인간 언어를 인식하고 분석한 뒤 다시 인간 언어로 답한다.
[이선희 기자 / 이석희 기자]
AI용 어휘 `말뭉치` 태부족…영어 2000억개 vs 한국어 2억개
기사입력2018.07.13 오후 5:43
최종수정2018.07.15 오후 1:50
◆ AI 인프라 외면한 정부 ◆
지난 5월 구글이 개발자대회에서 공개한 구글 어시스턴트는 사람처럼 가게에 전화를 걸어 점원과 자연스럽게 대화하며 예약을 수행해 전 세계를 놀라게 했다. 구글이 공개한 영상에 따르면 구글 어시스턴트는 전화상 음성이나 말투만 봤을 때 사람이라고 깜빡 속을 정도였다. 구글 어시스턴트는 "5월 3일 예약될까요"라고 말을 걸었다. 점원이 "잠깐만 기다리세요"라고 하자 "음…" 하며 기다리는 모습을 보였다. 상대방이 공손하게 부탁하면 칭찬을 섞어 답변도 한다. 상대의 맥락과 뉘앙스까지 파악하는 수준으로 향상된 것이다.
반면 국내 업체들이 내놓은 인공지능(AI) 어시스턴트는 말귀를 못 알아듣는다는 불만이 많다. 리서치기관 컨슈머인사이트가 지난 4월 전국 14~64세 휴대전화 사용자 1만2580명을 조사한 바에 따르면 AI 스피커 사용 경험자의 이용 만족률은 49%로 낮은 수준에 머물렀다. 불만족 이유는 '음성 명령이 잘 되지 않는다'(50%) '자연스러운 대화가 곤란하다'(41%) '소음을 음성 명령으로 오인한다'(36%) 등 순이었다. 컨슈머인사이트는 "국내 음성인식 스피커는 날씨나 일정 등 단순한 정보를 서툴게 검색하는 수준"이라고 했다.
AI 스피커, 챗봇 등 자연어 처리 기술에서 파생되는 시장은 급팽창하고 있다. AI 스피커만 해도 올해 말 전 세계 설치 대수가 지난해보다 2.5배 증가한 1억대에 이를 전망이다. 말뭉치는 이처럼 급성장하는 음성인식 분야의 '씨앗'과 같은 자원이다. 마치 어린아이가 책을 읽거나 TV를 보면서 스스로 언어를 배워가는 것처럼 기계도 많은 언어를 학습할수록 성능이 좋아지기 때문이다. 하지만 말의 뉘앙스 차이까지 구별할 정도로 기술력을 갖춘 외국 AI 스피커에 비해 국내 제품의 인식률이 떨어지는 이유는 무엇일까. 전문가들은 여러 가지 차이가 있겠지만 근본적으로 국가별로 구축해 놓은 언어 데이터베이스, 한마디로 말하면 컴퓨터용 국가별 언어 인프라스트럭처에 엄청난 차이가 벌어졌기 때문이라고 지적한다. 컴퓨터가 사람 말을 인식해서 이해한 다음 이를 다시 사람 말로 표현하려면 기본적으로 사람이 말하는 언어, 말뭉치를 컴퓨터용으로 구축해 둬야 한다.
미국, 일본, 중국은 민간 기업·대학·연구소와 손잡고 20년 넘게 대규모 말뭉치 구축 사업을 지속적으로 전개해 왔다. 영어권 국가인 영국·미국은 정부와 대학, 민간 연구소, 기업이 손잡고 1990년대 초반부터 일찌감치 영어 말뭉치 구축 사업을 시작했다. 미국, 영국, 캐나다 학계는 정부 지원 아래 말뭉치 통합 작업을 했고 이 방대한 데이터베이스는 미국 브리검영대 주도 아래 하나로 구축해 약 260억개 어절을 확보했다. 학계에 따르면 현재 영어는 2000억개 넘는 어절의 말뭉치가 구축된 것으로 알려졌다. 일본은 2006년부터 정부와 대학이 공동으로 '고토노하 프로젝트'를 진행했다. 현재는 약 40억개의 말뭉치를 확보하며 앞서가고 있다. 일본 국립국어연구소는 100억개 구축을 목표로 하고 있다. 중국은 2000년대부터 본격적으로 대만과 함께 국가 예산을 바탕으로 중국어 말뭉치 구축에 나서 현재는 800억개 이상 말뭉치가 구축돼 있다. 구글은 이미 10년 전에 1900억개 영어 말뭉치를 구축했다. 이를 토대로 컴퓨터가 학습을 하기 때문에 구글 AI는 시간이 지날수록 더 잘 인식할 수밖에 없다.
자연어 처리 기술자는 "언어를 기계가 학습한다는 것은 어느 정도 자료가 쌓여야 의미 있는 결과가 나오기 때문에 음성인식 기술 업력이 짧은 기업들이 딥러닝 기술을 확보해도 인식률이 떨어질 수밖에 없다"고 했다. 이 관계자는 "요즘에는 (걸그룹) '트와이스'라고 하면 걸그룹을 뜻하지만 과거 데이터를 학습한 기계는 '두 배'로 알아듣는다"며 "기 처리 기술은 음성 '인식' 단계에서 완성도가 떨어지기 때문에 제대로 된 서비스를 할 수 없다"고 했다. 예를 들어 세종 말뭉치를 구축한 '국립국어원 언어정보나눔터'에서 '먹었니'를 검색하면 2건만 검색된다. 한 개발자는 "통상 10억어절 이상은 돼야 딥러닝을 적용할 수 있는데 2건으로는 '먹었니'를 기계에 학습시킬 수 없다"고 했다.
'비트코인' '헬조선' 등 최근 사용되는 어휘 또한 찾아볼 수 없다. 이 프로젝트가 2007년 종료된 후 더는 진행되지 않았기 때문이다. 김한샘 연세대 언어정보연구원 교수가 쓴 '말뭉치 구축의 세계 동향과 국어 말뭉치의 현주소'에 따르면 세종 말뭉치는 1990년대가 7000만건, 2000년대가 1800만건으로 절반 이상이 1980년대 이전 자료에 치우쳐 있다.
■ <용어 설명>
▷ 말뭉치 : 자연어 처리 개발에 사용되는 언어 데이터를 모아놓은 덩어리(DB)다. 음성인식 인공지능 서비스는 자연어 처리 과정을 통해 인간 언어를 인식하고 분석한 뒤 다시 인간 언어로 답한다.
[이선희 기자 / 이석희 기자]